
Azure Site Recovery Overview
Microsoft introduced Azure Site Recovery (ASR) in 2014. This Disaster-Recovery-as-a-Service offering allows on-premisess workloads to be replicated into Azure, or another datacenter, to allow for rapid failover in the event of a major outage. At the time the service was narrowly focused on only those environments running Hyper-V and System Center Virtual Machine Manager. Since then the service has expanded to cover not only VMware environments, but has Azure region-to-region support in Preview. It has become the de facto method for migrating live workloads to Azure with minimal disruption. We’re going to review how to plan an ASR deployment for these newer capabilities.
Key Concepts
Azure Site Recovery works well in both directions – whether you are failing TO Azure to FROM Azure, the process is the same, as shown below:
Failover to Azure
- Servers are added to Replication under the Recovery Services vault in the Azure Portal
- The Process server begins replication and reduces the total amount of data to send to a minimum.
- Once replication has completed and a recovery point is taken, the servers will show “Protected” and can be perform a failover.
Failover from Azure
- Servers are “re-protected” under the Recovery Services vault in the Azure Portal. This reverses the direction of replication so that changes from the running server in Azure are replicated back on-premisess.
- The Process server begins replication and reduces the total amount of data to send to a minimum.
- Once replication has completed and a recovery point is taken, the servers will show “Protected” and can be perform a failover back to on-premisess.
VMware
Planning for replication of VMware-based workloads requires a thorough understanding of your environment. Variables such as number of total cores, IOPS requirements, daily churn rate, and required bandwidth must be defined and planned for to make ASR successful. Fortunately, Microsoft provides an excellent tool that can identify these key factors in your site recovery planning.
The Azure Site Recovery Deployment Planner is a profiling tool that continually monitors a VMware environment over a period and provides a report from this data that can guide resource planning including bandwidth requirements, storage account requirements, and machines that might be incompatible with ASR. The profiling parameters are set a runtime and can be defined by the user. It is recommended to capture 30 days of activity for a (typically) complete picture of resource utilization, including the all-important peaks in usage around month-end processing for many companies.
Below is a sample report dashboard produced by this tool:
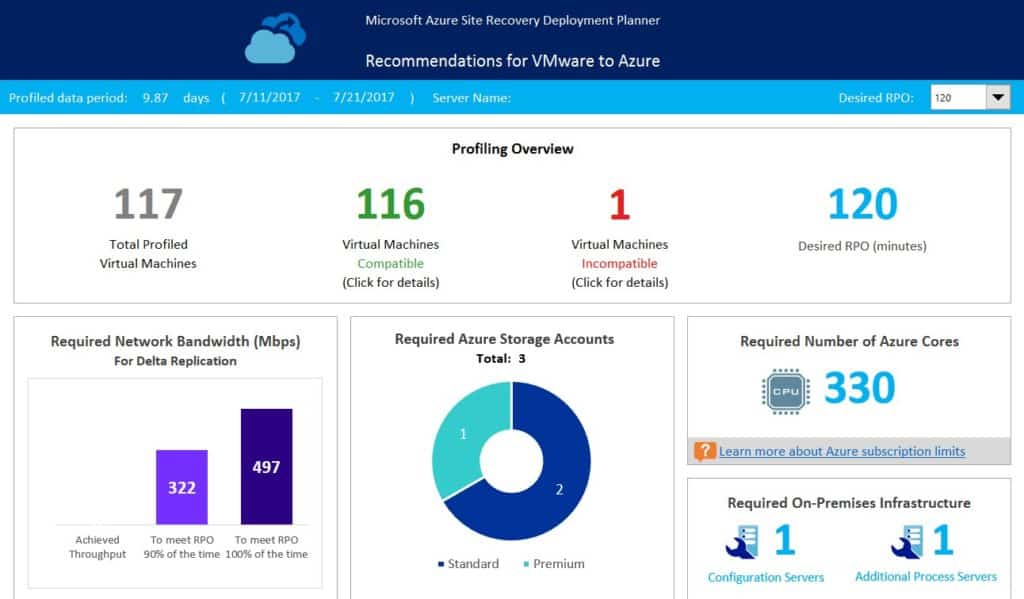
Figure 1 – Deployment Planner Report
The infrastructure required to handle the successful replication of the servers in this report are clearly stated. In the above screenshot, we can see that we need to plan for around 500Mbps of network bandwidth (based on this specific environment and Recovery Point Objective, or RPO, of 2 hours), 1 premium and 2 standard storage accounts, 330 total Azure cores, and 2 on-premisess servers to operate in the Configuration and Process server roles.
The sizing of the Configuration & Process servers is based on two factors: number of servers replicated, and daily churn rate. Below is the guidance from Microsoft on Configuration server sizing:
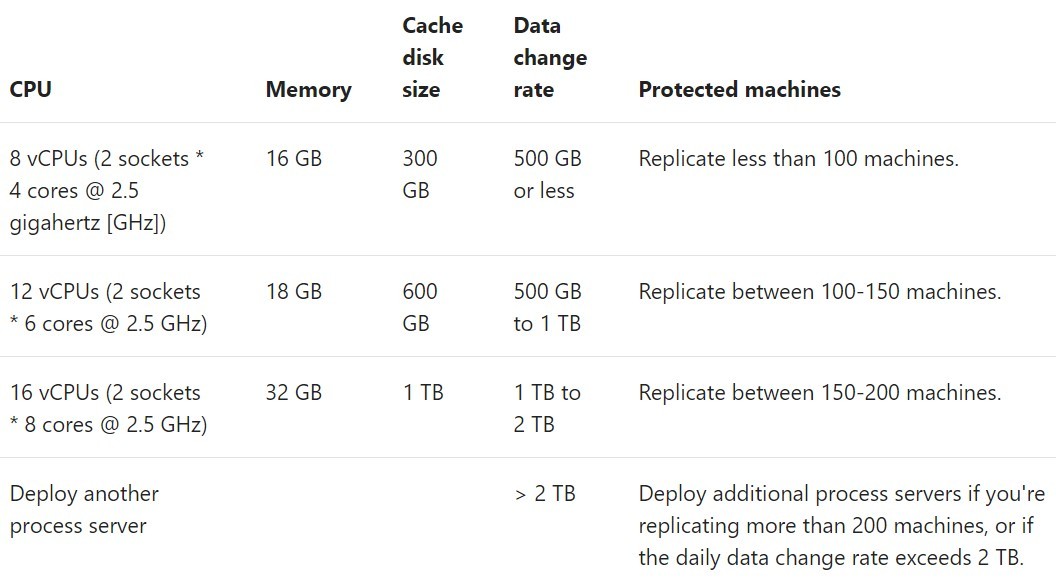
Figure 2 – Configuration Server Sizing
Process server sizing is similar, but slightly reduced since it doesn’t perform the Configuration role.
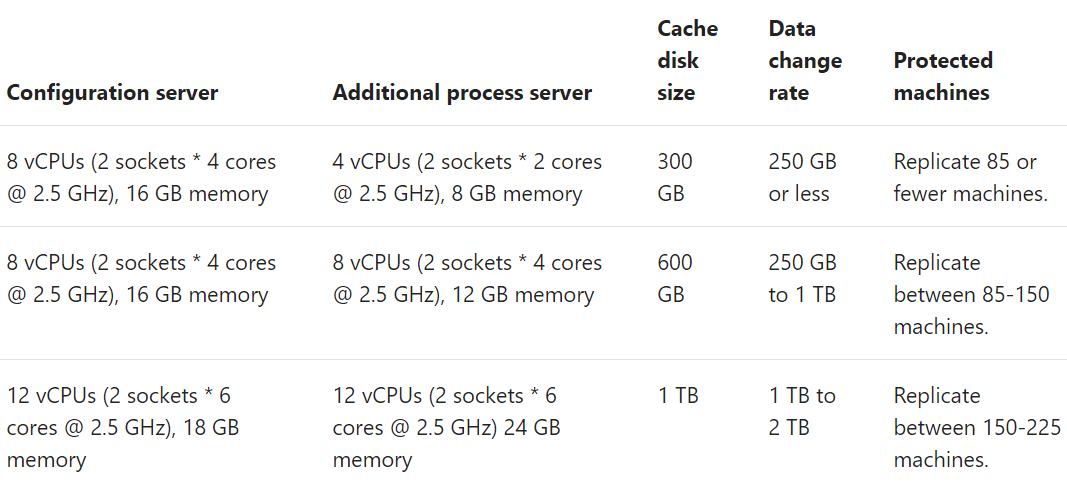
Figure 3 – Process Server Sizing
As shown from our sample report, we have 116 servers to replicate. While a single Configuration server would handle that number, the daily churn rate observed by the Deployment Planner warrants the additional Process server. With the prescribed infrastructure in place and the Configuration/Process servers sized correctly, VMware replication to Azure or another datacenter should be successful and result in each server showing “Protected” in the Recovery Services vault.
What about failback to on-premisess? For failback from Azure, IP connectivity between the Azure VNET and the on-premisess network must be available. This requires either a site-to-site IPSEC VPN, or Expressroute. Either will work. Failover to Azure does not require this VPN, only failback from Azure.
In addition, Microsoft’s guidance is that a Process server be deployed in Azure. This makes complete sense as the role of the Process server is to reduce and track the total amount of data to be replicated between sites. Replicating from Azure to on-premisess using the on-premisess Process server will work, but will be slower. How do we deploy a Process server in Azure? We use the Add Process Server option under the Configuration server view in the Azure Portal.

Figure 4 – Adding Process Server
The screenshot below shows all we need to configure for the new Process server, including subscription, resource group, subnet, server name, credentials, and IP address. Azure will then deploy a pre-configured IaaS (Infrastructure-as-a-Service) virtual machine in the designated resources. Opening remote desktop to this virtual machine launches the Process server configuration wizard, allowing you to associate it with your Configuration server just like you would an on-premisess Process server. With the Azure Process server registered, it becomes available to use for any failback replication activity.
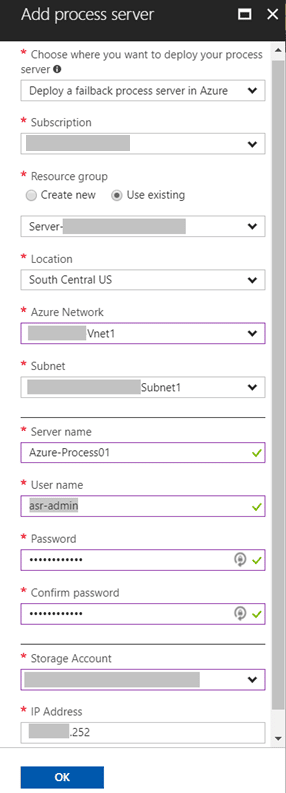
Figure 5 – Azure Process Server Options
Azure Region-to-Region
Region-to-Region replication uses the same methods and technology as shown above. However, there is one major difference: The Configuration/Process server is implemented as PaaS (platform-as-a-service). PaaS differs from IaaS (Infrastructure-as-a-service) in that the application functions normally but the infrastructure to support the application is abstracted from view and managed by Microsoft. In terms of ASR, this means that all replication is handled by a Microsoft-managed Configuration/Process server in the background. As a result, you do not need to plan for the resources needed to scale replication. You simply configure your Azure VM to replicate to the appropriate recovery services vault in the target region, and Azure takes care of the rest.
Why would you want or need ASR to replicate VMs in one region to another? If your VMs use GRS (geo-redundant storage) storage accounts, shouldn’t that accomplish the same thing? Short answer: no. GRS is a wonderful feature that ensures data availability in the event of an Azure region failure. “Azure region failure” is the key phrase here – the data is only available in the secondary region if the primary region fails. The vast majority of outages you are likely to experience are likely to be scoped to only your infrastructure/applications – human error, a configuration problem, etc… In other words, if your DR strategy depends on an Azure region failure, Microsoft will not be able to help make your data available.
In contrast, ASR gives you full control of when, where, and how VMs are failed to other regions independently of Azure region availability. Whereas GRS copies data between “paired” regions, you may elect to replicate VMs between non-paired regions depending on what makes the most sense for your business. This flexibility is unique to Azure and delivers tremendous value and simplicity for companies who understand that “cloud” does not equate to “DR” without proper planning.
As shown in the dialog below, the source resources are selected (no Configuration/Process server option).
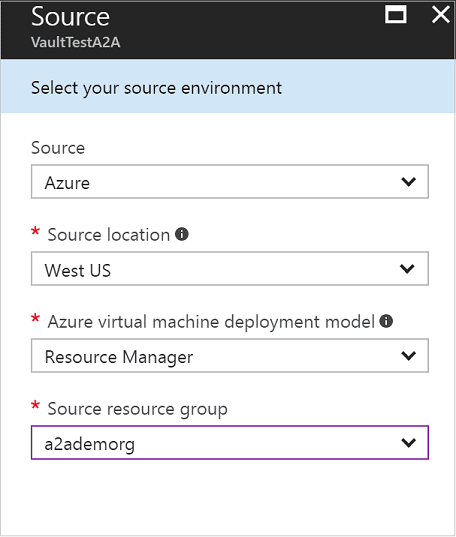
Figure 6 – https://docs.microsoft.com/en-us/azure/site-recovery/site-recovery-azure-to-azure
Once virtual machines are selected, the only target settings are the region, resource group, virtual network, and storage account.
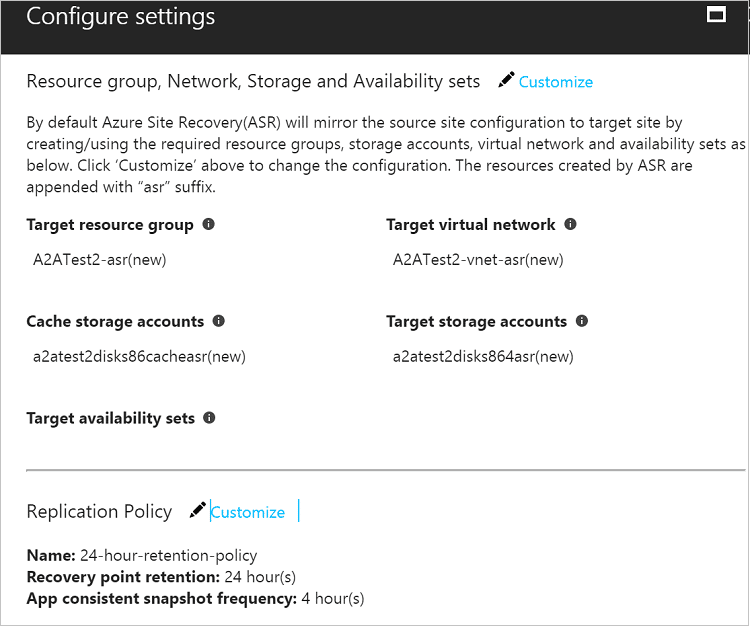
Figure 7 -https://docs.microsoft.com/en-us/azure/site-recovery/site-recovery-azure-to-azure
Summary
We’ve covered planning for ASR around VMware and Azure Region failover. By using the tools and growth considerations above, your DR project can be something that is rarely seen with DR – successful on the first try!




